VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)和 25.32% 的错误率夺得定位任务(Localization)的第一名(GoogLeNet 错误率为 26.44%)。VGG可以看成是加深版本的AlexNet. 都是conv layer + FC layer。
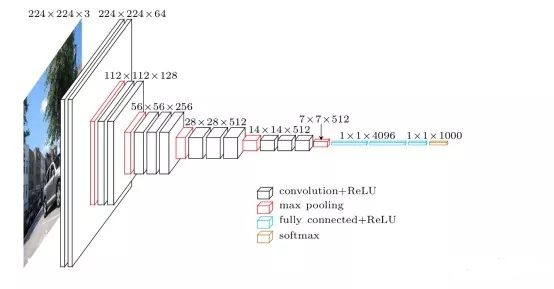
VGG网络结构
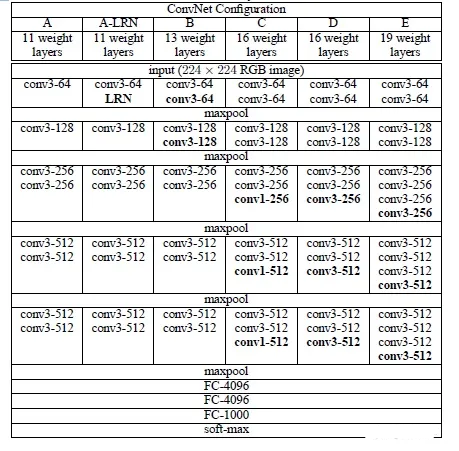
为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,先训练浅层的的简单网络 VGG11,再复用 VGG11 的权重来初始化 VGG13,如此反复训练并初始化 VGG19,能够使训练时收敛的速度更快。整个网络都使用卷积核尺寸为 3×3 和最大池化尺寸 2×2。
VGG代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class VGGNet(nn.Module):
def __init__(self, p):
super(VGGNet, self).__init__()
# VGG19前三层
self.conv1 = nn.Conv2d(1, 64, kernel_size = (3, 3), stride = 1)
self.conv2 = nn.Conv2d(64, 64, kernel_size = (2, 2), stride = 1)
self.pool1 = nn.MaxPool2d(kernel_size = (2, 2), stride = 2)
# 为保证网络深度, 在卷积层中加入padding
self.conv3 = nn.Conv2d(64, 128, kernel_size = (3, 3), stride = 1, padding = 1)
self.conv4 = nn.Conv2d(128, 128,kernel_size = (3, 3), stride = 1, padding = 1)
self.pool2 = nn.MaxPool2d(kernel_size = (2, 2), stride = 2)
self.conv5 = nn.Conv2d(128, 256, kernel_size = (3, 3), stride = 1, padding = 1)
self.conv6 = nn.Conv2d(256, 256, kernel_size = (3, 3), stride = 1, padding = 1)
self.conv7 = nn.Conv2d(256, 256, kernel_size = (3, 3), stride = 1, padding = 1)
self.conv8 = nn.Conv2d(256, 256, kernel_size = (3, 3), stride = 1, padding = 1)
self.pool3 = nn.MaxPool2d(kernel_size = (2, 2), stride = 2)
# 全连接层
self.dropout = nn.Dropout(p=p)
self.fc1 = nn.Linear(256*3*3, 1024)
self.fc2 = nn.Linear(1024, 1024)
self.fc3 = nn.Linear(1024, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.pool1(F.relu(x))
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(F.relu(x))
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.conv8(x)
x = self.pool3(F.relu(x))
x = torch.flatten(x, 1)
x = self.fc1(F.relu(x))
x = self.dropout(x)
x = self.fc2(F.relu(x))
x = self.dropout(x)
x = self.fc3(F.relu(x))
return x